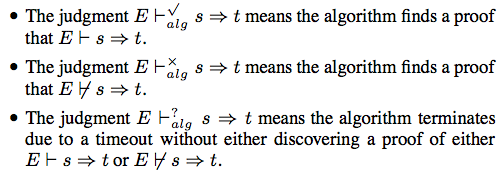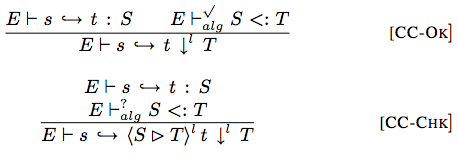I’ve been building an executable formalization of the POSIX shell semantics, which I’ve been calling smoosh (the Symbolic, Mechanized, Observable, Operational SHell).
I’m pleased to announce an important early milestone: smoosh passes the POSIX test suite (modulo locales, which smoosh doesn’t currently support). I’ve accordingly tagged this ‘morally correct’ verison as smoosh v0.1. You can play around with the latest version via the shtepper, a web-based frontend to a symbolic stepper. I think the shtepper will be particularly useful for those trying to learn the shell or to debug shell scripts.
There’s still plenty to do, of course: there are bugs to fix, quirks to normalize, features to implement, and tests to run. But please: play around with the smoosh shell and the shtepper, file bug reports, and submit patches!
We can tease apart the research on gradual types into two ‘lineages’: a pragmatic, implementation-oriented dynamic-first lineage and a formal, type-theoretic, static-first lineage. The dynamic-first lineage’s focus is on taming particular idioms—‘pre-existing conditions’ in untyped programming languages. The static-first lineage’s focus is on interoperation and individual type system features, rather than the collection of features found in any particular language. Both appear in programming languages research under the name “gradual typing”, and they are in active conversation with each other.
What are these two lineages? What challenges and opportunities await the static-first lineage? What progress has been made so far?
Their collapsible contracts are an implementation of the theory in my papers on space-efficient contracts (Space-Efficient Manifest Contracts from POPL 2015 and Space-Efficient Latent Contracts from TFP 2016). They use my merge algorithm to ‘collapse’ contracts and reduce some pathologically bad overheads. I’m delighted that my theory works with only a few bits of engineering cleverness:
Racket’s contracts are first-class values, which means subtle implementation details can impede detecting duplicates. Racket’s contract-stronger? seems to do a good enough job—though it helps that many contracts in Racket are just checking simple types.
There’s an overhead to using the merge strategy in both space and time. You don’t want to pay the price on every contract, but only for those that would consume unbounded space. Their implementation waits until something has been wrapped ten times before using the space-efficient algorithms.
Implication queries can be expensive; they memoize the results of merges.
I am particularly pleased to see the theory/engineering–model/implementation cycle work on such a tight schedule. Very nice!
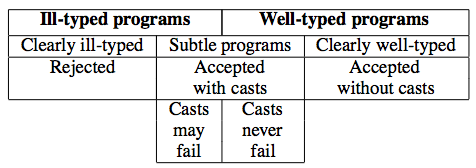
In hybrid type checking, a subtyping relationship between subset types {x:T|e} determines when it’s safe to omit a cast. The structural extension of subtyping to, e.g., function types, gives us a straightforward way to achieve verification by optimization: if we can prove that a cast is from a subtype to a supertype, there’s no need to pay the runtime cost of checking anything.
When should we reject a hybrid typed program? In Flanagan’s seminal paper, he offers a straightforward plan:
Flanagan enacts this plan by rejecting casts which are provably not from a subtype to a supertype: if the SMT solver finds that a cast might fail, then it rejects the program. In his model of an SMT solver, returning a checkmark (✓) when checking proves subtyping, a question mark (?) when checking times out, or an x-mark (×) when a counterexample of subtyping is found.
The compilation and checking judgment (a/k/a cast insertion) will insert a cast on successful or indeterminate checking, but has no rules for (and therefore rejects) programs where there is a counterexample.
Unfortunately, such a policy is too restrictive. For example, an SMT solver can easily prove that {x:Int|true} doesn’t imply {x:Int|even x}… but such a program shouldn’t be rejected! We should only reject programs that must fail.
When must a cast fail? When the two types are disjoint, i.e., when they don’t share any values. Since our language with casts has when the only normal form typeable at both types is an error. Cătălin HriÅ£cu got a good start on this in his thesis (see sections 2.4.6 and the end of 3.4.4), where he defines a notion of non-disjointness. He doesn’t define the notion for function types, but that’s actually very easy: so long as two function types are compatible (i.e., equal after erasure of refinements), they are non-disjoint. Why? Well, there’s at least one value that {x:T|e11}→{x:T|e12} and {x:T|e21}→{x:T|e22} have in common: λx. blame.
I can imagine a slightly stronger version: if the domain type is a refinement of base type, then we could exclude functions which could never even be called, i.e., with disjoint domains. At higher orders, though, there’s no way to tell (maybe the function in question never calls its argument), so I think the more liberal interpretation is the right starting point.
NB I briefly discuss when to reject hybrid-typed programs in my dissertation (Section 6.1.4).
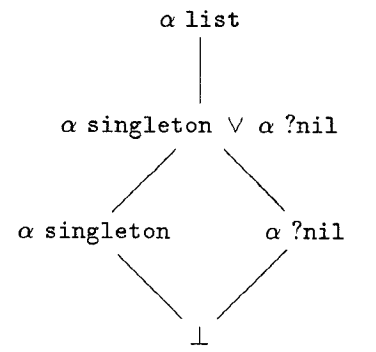
Frank Pfenning originated the idea of refinement types in his seminal PLDI 1991 paper with Tim Freeman. Freeman and Pfenning’s refinement types allow programmers to work with refined datatypes, that is, sub-datatypes induced by refining the set of available constructors. For example, here’s what that looks like for lists, with a single refinement type, ? singleton:
datatype ? list = nil | cons of ? * ? list
rectype ? singleton = cons ? nil
That is, a programmer defines a datatype ? list, but can identify refined types like ? singleton—lists with just one element. We can imagine a lattice of type refinements where ? list is at the top, but below it is the refinement of lists of length 0 or 1—written ? singleton ? ? nil. This type is itself refined by its constituent refinements, which are refined by the empty type. Here’s such a lattice, courtesy of a remarkably nice 1991-era TeX drawing:
Another way of phrasing all of this is that refinement types identify subsets of types. Back in 1983, Bengt Nordström and Kent Petersson introduced—as far as I know—the idea of subset types in a paper called Types and Specifications at the IFIP Congress. Unfortunately, I couldn’t find a copy of the paper, so it’s not clear where the notation {x:A|B(x)} set-builder-esque notation first came from, but it shows up in Bengt Nordström, Kent Petersson, and Jan M. Smith’s Programming in Martin-Löf’s Type Theory in 1990. Any earlier references would be appreciated. Update (2015-03-18):Colin Gordonpointed out that Robert Constable‘s Mathematics as programming from 1984 uses the subset type notation, as does the NUPRL tech report from 1983. The NUPRL TR came out in January ’83 while IFIP ’83 happened in September. Nate Foster, who works with Bob Constable, suspects that Constable has priority. Alright: subset types go to Robert Constable in January 1983 with the Nearly Ultimate Pearl. Going once…
My question is: when did we start calling {x:A | B(x)} and other similar subset types a “refinement type”? Any advice or pointers would be appreciated—I’ll update the post.
Susumu Hayashi in Logic of refinement types describes “ATTT”, which, according to the abstract, “has refi nement types which are intended to be subsets of ordinary types or specifications of programs”, where he builds up these refinements out of some set theoretic operators on singletons. By rights, this paper is probably the first to use “refinement type” to mean “subset type”… though I have some trouble pinpointing where the paper lives up to that claim in the abstract.
Besides the built-in type families int, bool, and array, any user-defined data type may be refined by explicit declarations. …
typeref ? list of nat
with nil <| ? list(0)
| :: <| {n:nat} ? * ? list(n) -> ? list(n+1)
Later on, in Section 3.1, they have a similar use of the term:
In the standard basis we have refined the types of many common functions on integers such as addition, subtraction, multiplication, division, and the modulo operation. For instance,
+ <| {m:int} {n:int} int(m) * int(n) -> int(m+n)
is declared in the system. The code in Figure 3 is an implementation of binary search through an array. As before, we assume:
sub <| {n:nat} {i:nat | i < n} ? array(n) * int(i) -> ?
So indices allow users to refine types, though they aren’t quite refinement types. In 1999, Xi and Pfenning make a strong distinction in Dependent Types in Practical Programming; from Section 9:
…while refinement types incorporate intersection and can thus ascribe multiple types to terms in a uniform way, dependent types can express properties such as “these two argument lists have the same length” which are not recognizable by tree automata (the basis for type refinements).
Now, throughout the paper they do things like “refine the datatype with type index objects” and “refine the built-in types: (a) for every integer n, int(n) is a singleton type which contains only n, and (b) for every natural number n, 0 a array(n) is the type of arrays of size n”. So here there’s a distinction between “refinement types”—the Freeman and Pfenning discipline—and a “refined type”, which is a subset of a type indicated by some kind of predicate and curly braces.
… the datasort refinements (often called refinement types) of Freeman, Davies, and Pfenning, and the index refinements of Xi and Pfenning. Both systems refine the simple types of Hindley-Milner type systems.
In her 2004 paper with Frank, Tridirectional Typechecking, she maintains the distinction between refinements, but uses a term I quite like—“property types”, i.e., types that guarantee certain properties.
Yitzhak Mandelbaum, my current supervisor David Walker, and Bob Harper wrote An Effective Theory of Type Refinements in 2003, but they didn’t quite have subset types. Their discussion of related work makes it seem that they interpret refinement types as just about any device that allows programmers to use the existing types of a language more precisely:
Our initial inspiration for this project was derived from work on refinement types by Davies and Pfenning and Denney and the practical dependent types proposed by Xi and Pfenning. Each of these authors proposed to sophisticated type systems that are able to specify many program properties well beyond the range of conventional type systems such as those for Java or ML.
Cormac Flanagan‘s Hybrid Type Checking in 2006 is probably the final blow for any distinction between datasort refinements and index refinements: right there on page 3, giving the syntax for types, he writes “{x:B|t} refinement type“. He says on the same page, at the beginning of Section 2, “Our refinement types are inspired by prior work on decidable refinement type systems”, citing quite a bit of the literature: Mandelbaum, Walker, and Harper; Freeman and Pfenning; Davies and Pfenning ICFP 2000; Xi and Pfenning 1999; Xi LICS 2000; and Ou, Tan, Mandelbaum, and Walker. After Cormac, everyone just seems to call them refinement types: Ranjit Jhala‘s Liquid Types, Robby Findler and Phil Wadler in Well typed programs can’t be blame, my own work, Andy Gordon in Semantic Subtyping with an SMT Solver. This isn’t a bad thing, but perhaps we can be more careful with names. Now that we’re all in the habit of calling them refinements, I quite like “indexed refinements” as a distinction. Alternatively, “subset types” are a very clear term with solid grounding in the literature.
Edited to add: thanks to Ben Greenman for some fixes to broken links and to Lindsey Kuper and Ron Garcia for helping me clarify what refines what.
2020-04-27 update:Shriram Krishnamurthi suggests that Robert (Corky) Cartwright had a notion of “refinement type” in “User-Defined Data Types as an Aid to Verifying LISP Programs” from ICALP 1976 and with John McCarthy in First order programming logic in POPL 1979. I haven’t been able to get a PDF copy of the ICALP paper (please send me one if you can find it!). The POPL paper is clearly related:
The key idea underlying our formal systems is that recursive definitions of partial functions can be interpreted as equations extending a first order theory of the program domain.
Their model is typed, and the paper is about how Corky and John independently discovered ways of addressing recursion/fixed points. They translate programs to logic, treating checks in negative positions as ?‚ like Blume and McAllester’s “A sound (and complete) model of contracts”, but they don’t seem to think of themselves as actually refining types per se. This paper is an interesting early use of an SMT-like logic to prove properties of programs… though they do the proofs by hand!
The auxiliary function ATOMLIST [a program predicate] serves as a clumsy mechanism for specifying the implicit data type atom-list [which he defined by hand]. If we included atom-list as a distinct, explicit data type in our programming language and expanded our first-order theory to include atom-lists as well as S-expressions, the informal proof using induction on atom-lists [given earlier] could be formalized directly in our first order system. However, since LISP programs typically involve a wide variety of abstract data types, simply adding a few extra data types such as atom-list to LISP will not eliminate the confusion caused by dealing with abstract data type representations rather than the abstract types themselves. In fact, the more complex that an abstract type is, the more confusing that proofs involving its representations are likely to be. Consequently, I decided that the best solution to this problem is to include a comprehensive data type definition facility in LISP and to formally define the semantics of a program P by creating a first-order theory for the particular data types defined in P. The resulting language TYPED LISP is described in the next chapter.
I’m really happy to be part of the first PLVNET, a workshop on the intersection of PL, verification, and networking. I have two abstracts up for discussion.
The first abstract, Temporal NetKAT, is about adding reasoning about packet histories to a network policy language like NetKAT. The work on this is moving along quite nicely (thanks in large part to Ryan Beckett!), and I’m looking forward to the conversations it will spark.
The second abstract, Type systems for SDN controllers, is about using type systems to statically guarantee the absence of errors in controller programs. Fancy new switches have tons of features, which can be tricky to operate—can we make sure that a controller doesn’t make any mistakes when it talks to a switch? Some things are easy, like making sure that the match/action rules are sent to tables that can handle them; some things are harder, like making sure the controller doesn’t fill up a switch’s tables. I think this kind of work is a nice complement to the NetKAT “whole policy” approach, a sort of OpenFlow 1.3+ version of VeriCon with slightly different goals.
The standard algorithm for higher-order contract checking can lead to unbounded space consumption and can destroy tail recursion, altering a program’s asymptotic space complexity. While space efficiency for gradual types—contracts mediating untyped and typed code—is well studied, sound space efficiency for manifest contracts—contracts that check stronger properties than simple types, e.g., “is a natural” instead of “is an integer”—remains an open problem.
We show how to achieve sound space efficiency for manifest contracts with strong predicate contracts. The essential trick is breaking the contract checking down into coercions: structured, blame-annotated lists of checks. By carefully preventing duplicate coercions from appearing, we can restore space efficiency while keeping the same observable behavior.
The conference version is a slightly cut down version of my submission, focusing on the main result: eidetic λH is a space-efficient manifest contract calculus with the same operational behavior as classic λH. More discussion and intermediate results—all in a unified framework for space efficiency—can be found in the technical report on the arXiv.
The key insight is that … we must recursively deconstruct higher-order types down to their first-order parts, solve for those …, and then reconstruct the higher-order parts … . [Emphasis theirs]
Now, they’re deconstructing “flows” in their type inference and I’m deconstructing types themselves. They have to be careful about what’s known in the program and what isn’t, and I have to be careful about blame labels. But in both cases, a proper treatment of errors creates some asymmetries. And in both cases, the solution is to break everything down to the first-order checks, reconstructing a higher-order solution afterwards.
The “make it all first order” approach contrasts with subtyping approaches (like in Well Typed Programs Can’t Be Blamed and Threesomes, with and without blame). I think it’s worth pointing out that as we begin to consider blame, contract composition operators look less and less like meet operations and more like… something entirely different. Should contracts with blame inhabit some kind of skew lattice? Something else?
I highly recommend the Rastogi et al. paper, with one note: when they say kind, I think they mean “type shape” or “type skeleton”—not “kind” in the sense of classifying types and type constructors. Edited to add: also, how often does a type inference paper include a performance evaluation? Just delightful!
The standard algorithm for higher-order contract checking can lead to unbounded space consumption and can destroy tail recursion, altering a program’s asymptotic space complexity. While space efficiency for gradual types—contracts mediating untyped and typed code—is well studied, sound space efficiency for manifest contracts—contracts that check stronger properties than simple types, e.g., “is a natural” instead of “is an integer”—remains an open problem.
We show how to achieve sound space efficiency for manifest contracts with strong predicate contracts. We define a framework for space efficiency, traversing the design space with three different space-efficient manifest calculi. Along the way, we examine the diverse correctness criteria for contract semantics; we conclude with a language whose contracts enjoy (galactically) bounded, sound space consumption—they are observationally equivalent to the standard, space-inefficient semantics.
In a Software-Defined Network (SDN), a central, computationally powerful controller manages a set of distributed, computationally simple switches. The controller computes a policy describing how each switch should route packets and populates packet-processing tables on each switch with rules to enact the routing policy. As network conditions change, the controller continues to add and remove rules from switches to adjust the policy as needed.
Recently, the SDN landscape has begun to change as several proposals for new, reconfigurable switching architectures, such as RMT and FlexPipe have emerged. These platforms provide switch programmers with many, flexible tables for storing packet-processing rules, and they offer programmers control over the packet fields that each table can analyze and act on. These reconfigurable switch architectures support a richer SDN model in which a switch configuration phase precedes the rule population phase. In the configuration phase, the controller sends the switch a graph describing the layout and capabilities of the packet processing tables it will require during the population phase. Armed with this foreknowledge, the switch can allocate its hardware (or software) resources more efficiently.
We present a new, typed language, called Concurrent NetCore, for specifying routing policies and graphs of packet-processing tables. Concurrent NetCore includes features for specifying sequential, conditional and concurrent control-flow between packet- processing tables. We develop a fine-grained operational model for the language and prove this model coincides with a higher level denotational model when programs are well typed. We also prove several additional properties of well typed programs, including strong normalization and determinism. To illustrate the utility of the language, we develop linguistic models of both the RMT and FlexPipe architectures and we give a multi-pass compilation algorithm that translates graphs and routing policies to the RMT model.