Frank Pfenning originated the idea of refinement types in his seminal PLDI 1991 paper with Tim Freeman. Freeman and Pfenning’s refinement types allow programmers to work with refined datatypes, that is, sub-datatypes induced by refining the set of available constructors. For example, here’s what that looks like for lists, with a single refinement type, ? singleton:
datatype ? list = nil | cons of ? * ? list rectype ? singleton = cons ? nil
That is, a programmer defines a datatype ? list, but can identify refined types like ? singleton—lists with just one element. We can imagine a lattice of type refinements where ? list is at the top, but below it is the refinement of lists of length 0 or 1—written ? singleton \/ ? nil. This type is itself refined by its constituent refinements, which are refined by the empty type. Here’s such a lattice, courtesy of a remarkably nice 1991-era TeX drawing:
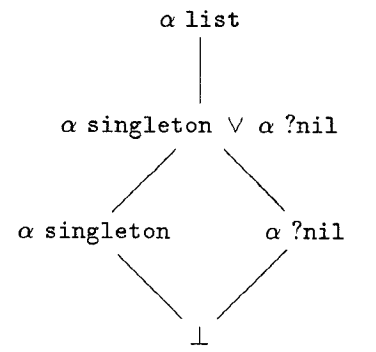
Another way of phrasing all of this is that refinement types identify subsets of types. Back in 1983, Bengt Nordström and Kent Petersson introduced—as far as I know—the idea of subset types in a paper called Types and Specifications at the IFIP Congress. Unfortunately, I couldn’t find a copy of the paper, so it’s not clear where the set-builder-esque notation {x:A|B(x)} notation first came from, but it shows up in Bengt Nordström, Kent Petersson, and Jan M. Smith’s Programming in Martin-Löf’s Type Theory in 1990. Any earlier references would be appreciated. Update (2015-03-18): Colin Gordon pointed out that Robert Constable‘s Mathematics as programming from 1984 uses the subset type notation, as does the NUPRL tech report from 1983. The NUPRL TR came out in January ’83 while IFIP ’83 happened in September. Nate Foster, who works with Bob Constable, suspects that Constable has priority. Alright: subset types go to Robert Constable in January 1983 with the Nearly Ultimate Pearl. Going once…
My question is: when did we start calling {x:A | B(x)} and other similar subset types a “refinement type”? Any advice or pointers would be appreciated—I’ll update the post.
Susumu Hayashi in Logic of refinement types describes “ATTT”, which, according to the abstract, “has refinement types which are intended to be subsets of ordinary types or specifications of programs”, where he builds up these refinements out of some set theoretic operators on singletons. By rights, this paper is probably the first to use “refinement type” to mean “subset type”… though I have some trouble pinpointing where the paper lives up to that claim in the abstract.
Ewen Denney was using refinement types to mean types and specifications augmented with logical propositions. This terminology shows up in his 1998 PhD thesis and his 1996 IFIP paper, Refinement Types for Specification.
In 1998, Hongwei Xi and Frank Pfenning opened the door to flexible interpretations of “refinements” in Eliminating Array Bound Checking Through Dependent Types. In Section 2.4, they use ‘refinement’ in a rather different sense:
Besides the built-in type families int, bool, and array, any user-defined data type may be refined by explicit declarations. …
typeref ? list of nat with nil <| ? list(0) | :: <| {n:nat} ? * ? list(n) -> ? list(n+1)
Later on, in Section 3.1, they have a similar use of the term:
In the standard basis we have refined the types of many common functions on integers such as addition, subtraction, multiplication, division, and the modulo operation. For instance,
+ <| {m:int} {n:int} int(m) * int(n) -> int(m+n)is declared in the system. The code in Figure 3 is an implementation of binary search through an array. As before, we assume:
sub <| {n:nat} {i:nat | i < n} ? array(n) * int(i) -> ?
So indices allow users to refine types, though they aren’t quite refinement types. In 1999, Xi and Pfenning make a strong distinction in Dependent Types in Practical Programming; from Section 9:
…while refinement types incorporate intersection and can thus ascribe multiple types to terms in a uniform way, dependent types can express properties such as “these two argument lists have the same length” which are not recognizable by tree automata (the basis for type refinements).
Now, throughout the paper they do things like “refine the datatype with type index objects” and “refine the built-in types: (a) for every integer n, int(n) is a singleton type which contains only n, and (b) for every natural number n, 0 a array(n) is the type of arrays of size n”. So here there’s a distinction between “refinement types”—the Freeman and Pfenning discipline—and a “refined type”, which is a subset of a type indicated by some kind of predicate and curly braces.
Jana Dunfield published a tech report in 2002, Combining Two Forms of Type Refinements, where she makes an impeccably clear distinction:
… the datasort refinements (often called refinement types) of Freeman, Davies, and Pfenning, and the index refinements of Xi and Pfenning. Both systems refine the simple types of Hindley-Milner type systems.
In her 2004 paper with Frank, Tridirectional Typechecking, she maintains the distinction between refinements, but uses a term I quite like—“property types”, i.e., types that guarantee certain properties.
Yitzhak Mandelbaum, my current supervisor David Walker, and Bob Harper wrote An Effective Theory of Type Refinements in 2003, but they didn’t quite have subset types. Their discussion of related work makes it seem that they interpret refinement types as just about any device that allows programmers to use the existing types of a language more precisely:
Our initial inspiration for this project was derived from work on refinement types by Davies and Pfenning and Denney and the practical dependent types proposed by Xi and Pfenning. Each of these authors proposed to sophisticated type systems that are able to specify many program properties well beyond the range of conventional type systems such as those for Java or ML.
In the fairly related and woefully undercited 2004 paper, Dynamic Typing with Dependent Types, Xinming Ou, Gang Tan, Yitzhak Mandelbaum, and David Walker used the term “set type” to define {x:A | B(x)}.
Cormac Flanagan‘s Hybrid Type Checking in 2006 is probably the final blow for any distinction between datasort refinements and index refinements: right there on page 3, giving the syntax for types, he writes “{x:B|t} refinement type“. He says on the same page, at the beginning of Section 2, “Our refinement types are inspired by prior work on decidable refinement type systems”, citing quite a bit of the literature: Mandelbaum, Walker, and Harper; Freeman and Pfenning; Davies and Pfenning ICFP 2000; Xi and Pfenning 1999; Xi LICS 2000; and Ou, Tan, Mandelbaum, and Walker. After Cormac, everyone just seems to call them refinement types: Ranjit Jhala‘s Liquid Types, Robby Findler and Phil Wadler in Well typed programs can’t be blame, my own work, Andy Gordon in Semantic Subtyping with an SMT Solver. This isn’t a bad thing, but perhaps we can be more careful with names. Now that we’re all in the habit of calling them refinements, I quite like “indexed refinements” as a distinction. Alternatively, “subset types” are a very clear term with solid grounding in the literature.
Finally: I didn’t cite it in this discussion, but Rowan Davies‘s thesis, Practical Refinement-Type Checking, was extremely helpful in looking through the literature.
Edited to add: thanks to Ben Greenman for some fixes to broken links and to Lindsey Kuper and Ron Garcia for helping me clarify what refines what.
2020-04-27 update: Shriram Krishnamurthi suggests that Robert (Corky) Cartwright had a notion of “refinement type” in “User-Defined Data Types as an Aid to Verifying LISP Programs” from ICALP 1976 and with John McCarthy in First order programming logic in POPL 1979. I haven’t been able to get a PDF copy of the ICALP paper (please send me one if you can find it!). The POPL paper is clearly related:
The key idea underlying our formal systems is that recursive definitions of partial functions can be interpreted as equations extending a first order theory of the program domain.
Their model is typed, and the paper is about how Corky and John independently discovered ways of addressing recursion/fixed points. They translate programs to logic, treating checks in negative positions as ?‚ like Blume and McAllester’s “A sound (and complete) model of contracts”, but they don’t seem to think of themselves as actually refining types per se. This paper is an interesting early use of an SMT-like logic to prove properties of programs… though they do the proofs by hand!
Cartwright’s dissertation, A Practical Formal Semantic Definition and Verification System for Typed Lisp (which I’ve hosted here, since I could only find it on a very slow server elsewhere) makes it clear that the work is indeed very closely related. Here’s a long quote from the end of his introduction:
The auxiliary function ATOMLIST [a program predicate] serves as a clumsy mechanism for specifying the implicit data type atom-list [which he defined by hand]. If we included atom-list as a distinct, explicit data type in our programming language and expanded our first-order theory to include atom-lists as well as S-expressions, the informal proof using induction on atom-lists [given earlier] could be formalized directly in our first order system. However, since LISP programs typically involve a wide variety of abstract data types, simply adding a few extra data types such as atom-list to LISP will not eliminate the confusion caused by dealing with abstract data type representations rather than the abstract types themselves. In fact, the more complex that an abstract type is, the more confusing that proofs involving its representations are likely to be. Consequently, I decided that the best solution to this problem is to include a comprehensive data type definition facility in LISP and to formally define the semantics of a program P by creating a first-order theory for the particular data types defined in P. The resulting language TYPED LISP is described in the next chapter.
This is perpetually vexing. I’ve had to explain in several different reviews that Freeman and Pfenning did not invent refinement types in the way that the term is now used. I think people see “Refinement types” in the title of that paper and assume it must be about {x:Ï„|P(x)}. (Aside: It’s been widely believed for years that you can encode a datasort refinement system as an index refinement system, but AFAIK no one’s actually done it.)
CMU’s invention of “type refinement” as a notion for a wide range of stuff including datasort refinements didn’t catch on. It’s possible that trying to simultaneously rename “refinement type” to “datasort refinement” *and* introduce a new term “type refinement” was doomed, but why did “refinement type” have to get mutated in place?
(By a strange coincidence, I was just thinking about whether indexed types *are* refinement types in the current sense. Or, rather, whether refinement types are indexed types. I think they probably are, via singletons and the guarded/asserting types from my thesis, but I haven’t worked it out, so I’m just blowing smoke, so far.)
Atkey, Johann, and Ghani relate type refinements and dependent inductive types in When is a Type Refinement an Inductive Type?. More recently, Sekiyama, Nishida, and Igarashi move statically and dynamically between datasort refinements and index refinements in Manifest Contracts for Datatypes. I’m not sure if either of those quite fit the bill of what you’ve been wondering, but they’re both great papers in any case.
The confusion makes sense—datasort refinements are identifying subsets, index refinements are also identifying subsets. But the techniques involved in using the two are so different. I agree with you: it’s worth keeping the nomenclature clear.
I’ve never been able to understand the first paper, but I should probably keep trying.
I’ve only read an earlier version of the second paper, so take this with double the usual grains of salt, but I’m pretty sure it doesn’t have datasort refinements. They talk about “refinements on data constructors”, but I would say they’re translating refinement types (or index refinements) into refinement types. If you look at slist2 in the introduction, it still has {x:T|e} types; it’s just formulated differently than their slist1. (slist2 is very close to Xi’s DML. The difference is that in DML, you’d index slist2 by its smallest element, rather than talk about “head xs” inside e; you also need some kind of hack to get the effect of indexing SNil by +∞.) In fact, you can’t express the sortedness of a list with just datasorts; you’d need as many datasorts as you have integers.
They also don’t have subtyping; without subtyping, datasorts wouldn’t be worth much.
Yes, our work doesn’t answer Jana’s question (but I think it may indicate possibility for doing so). To relate “type refinement” to “datasort refinement” (in the sense of Freeman–Pfenning), I think we need at least two mechanisms. One is subtyping, which is pointed out by Jana. The other is an join-like operator of two type refinements. (A such operator isn’t trivial in our setting because each refinement can refine the datatype different from the other.)
“Type refinement” is a long-term research program that I started in the late 1980’s. My goals in this enterprise have drifted somewhat over time, but I would summarize them as (a) capture more precise properties of programs that we already know to be well-typed in a simpler discipline in order to catch more errors, and (b) retain the good theoretical and practical properties of the simpler disciplines such as effective type checking. Of course, (c) you want all the other good things like usability, modularity, elegance, etc., just as for any system of types.
The first system we came up with was heavily influenced by four things: those pesky “inexhaustive pattern match” warnings in ML, John Reynolds’ work on intersection types that solved a deep problem for us, abstract interpretation, and order-sorted typing that was investigated for logic programming at the time. Since we (that is, Tim Freeman and I) didn’t see anything on the horizon satisfying (a), (b), and (c), we called them just “refinement types”. With a crystal ball, we should have called them “datasort refinements”, and that’s what I like to use now. “Index refinements” (the work with Hongwei Xi) were also designed to satisfy (a), (b), and (c), so they are an example of “type refinement” (the research program), but distinct from “refinement types” in their original meaning as datasort refinements.
General subset types aren’t quite an example of what we meant, because type checking with arbitrary subset types is both undecidable and impractical. But subset types {x:T|P(x)} could satisfy our goals as long as P is drawn from a tractable domain and the whole system that includes them hangs together.